Servers are a uniquely important piece of your business. They aren’t your core product, but your product can’t exist without them. While you want to be budget-conscious, your servers and architecture are among the few aspects of your business where you mustn’t let saving money get in the way of doing it right.
If you don’t have an experienced system administrator on your team, then one of your first tasks should be to find someone with that experience. This person or team may only work with you two to five hours a month, but these will be essential hours. It can be challenging to get your application’s architecture right at this point, but a good system administrator can help you do that.
Before we get too deeply into architecture, I want to talk about SSL. You should build your application so that every single page is served over SSL. This includes your marketing site. Don’t hesitate–just do it. Build your app with full-time SSL from day one. Every. Single. Page. Use SSL, HSTS, and secure cookies. There’s no excuse not to do it: the performance and cost are both negligible. You’d spend more time and effort trying to make your application handle both SSL and non-SSL pages than you would if you were to stick with SSL throughout. I’d also suggest paying for multiple years at a time when you buy your certificate–if you don’t, your certificate might expire a year from now at the least convenient time. Trust me: you’ll have much more important things to focus on during those first couple of years.
Let’s take a look at the stages of a basic web application. During development, you should start simply and delay complexity. As you move closer to your beta and your launch, you’ll want to build a scalable architecture with multiple layers of redundancy for your backups. How far you take it is up to you and your business. I’m not trying to turn you into a system administrator, but I’d like to help you understand the benefits of a modular and scalable architecture for your application.
The following recommendations are focused on redundancy (your ability to weather problems) and scalability (your ability to increase your capacity). A single virtual machine can handle an incredible amount of traffic; but it’s also inherently risky to put your entire application on a single virtual server.
The following advice is only the tip of the iceberg when it comes scaling. It can quickly become much more complex than what we’ll look at here, but this should be more than enough for all but the most explosive companies to make it through the first year or two–if not longer.
Web, Application, and Database Servers
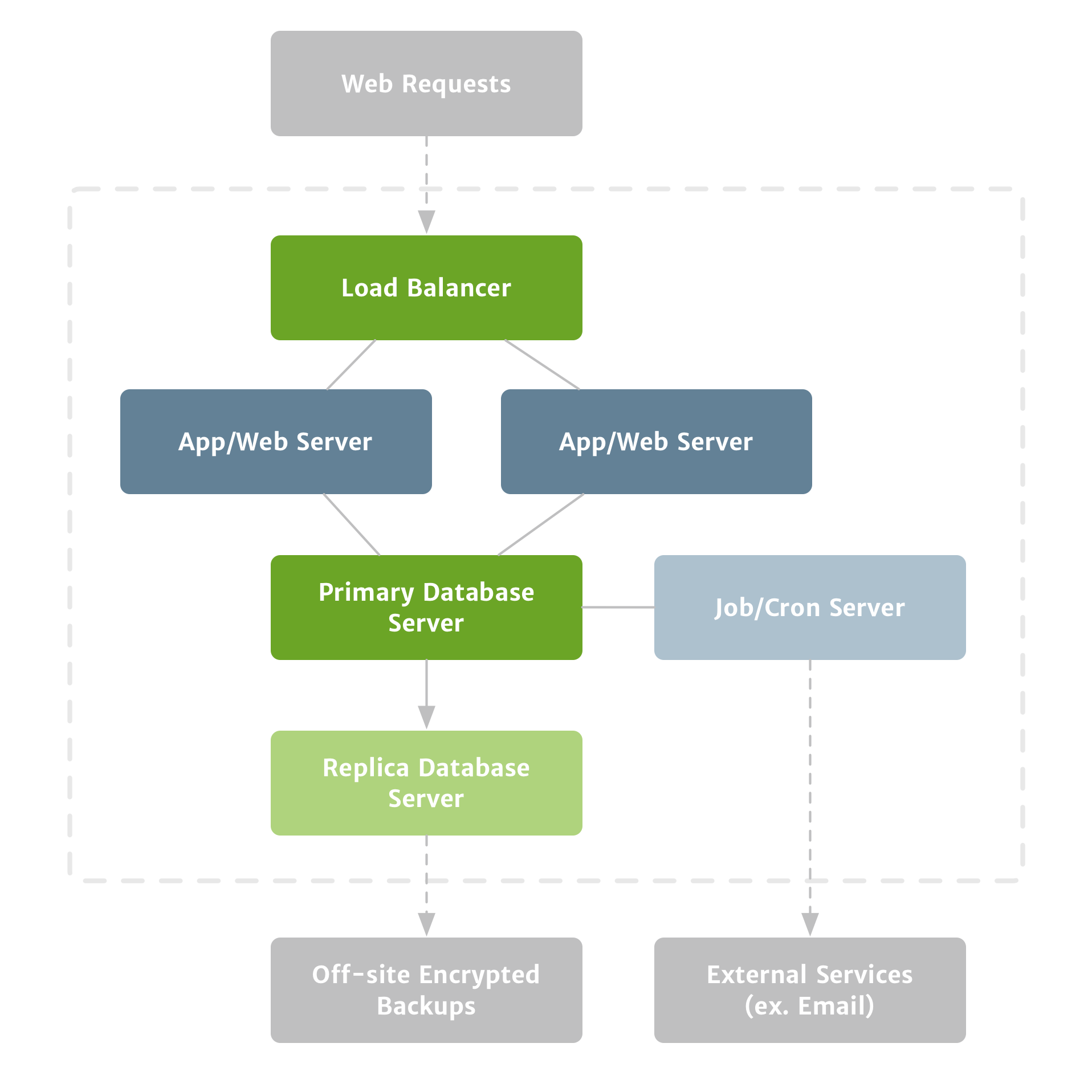
A modern web application can’t get much simpler than having a web server, an application server, and a database server. Your web and application servers are essentially stateless; they’ll handle all the requests, and they’ll communicate with your customers’ web browsers. Your goal should be to design your system so that your web and application servers can be upgraded, replaced, deleted, or rebuilt without any consequences. For instance, you might create a duplicate application server with more resources or different software, and then simply update your domain to point to the new application server. (Figure 1)
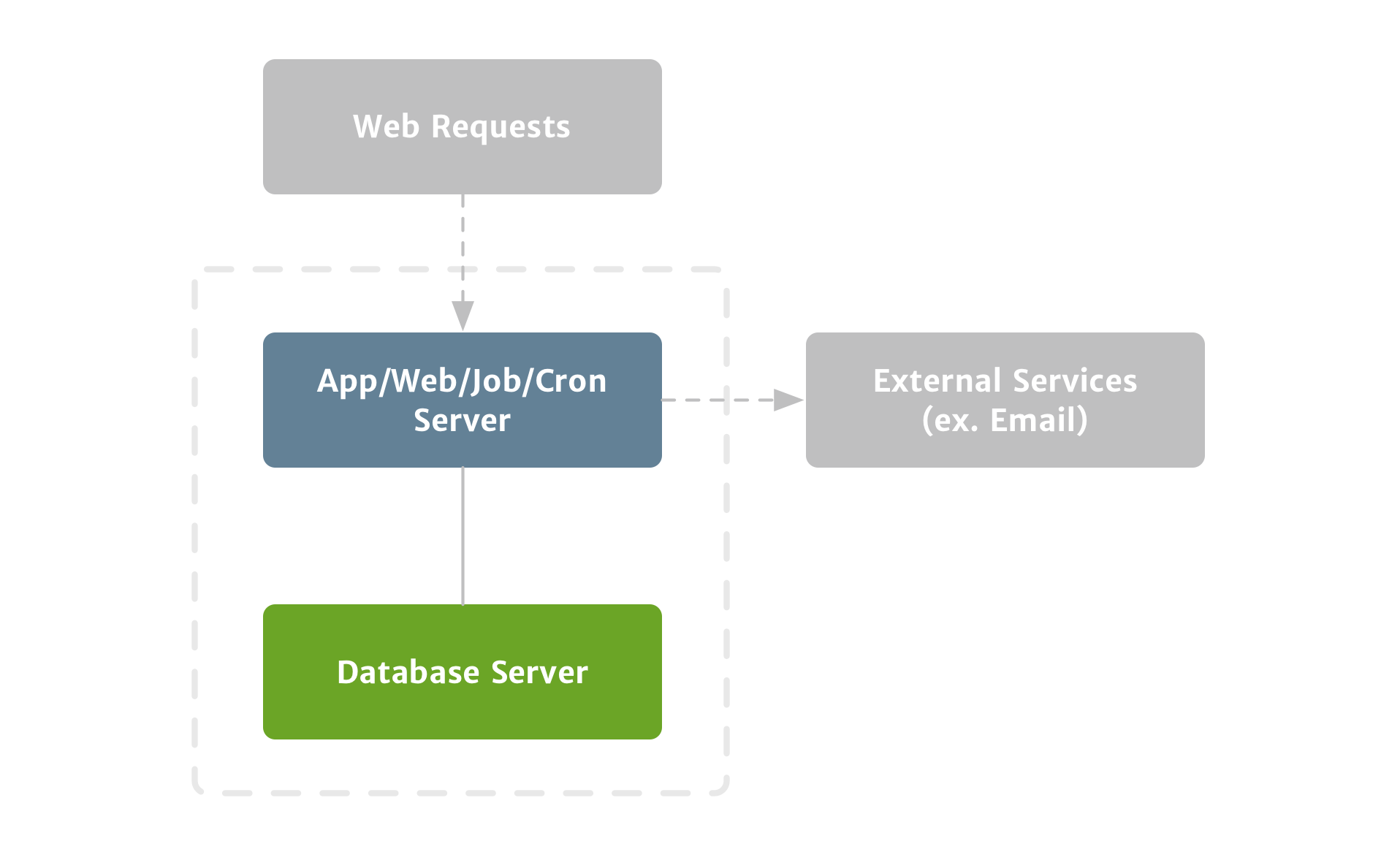
The starting point for any production web application. Before launch, you’ll want to add a functional backup process.
↩︎Replica Database
The next step–and one of the keys to taking care of your customers’ data–is a replica database, or essentially a live copy of your production database. This ensures that if something takes your primary database offline, you’ll have an exact replica to prevent any data loss. And it ensures that you can get back up and running quickly and easily. (Figure 2)
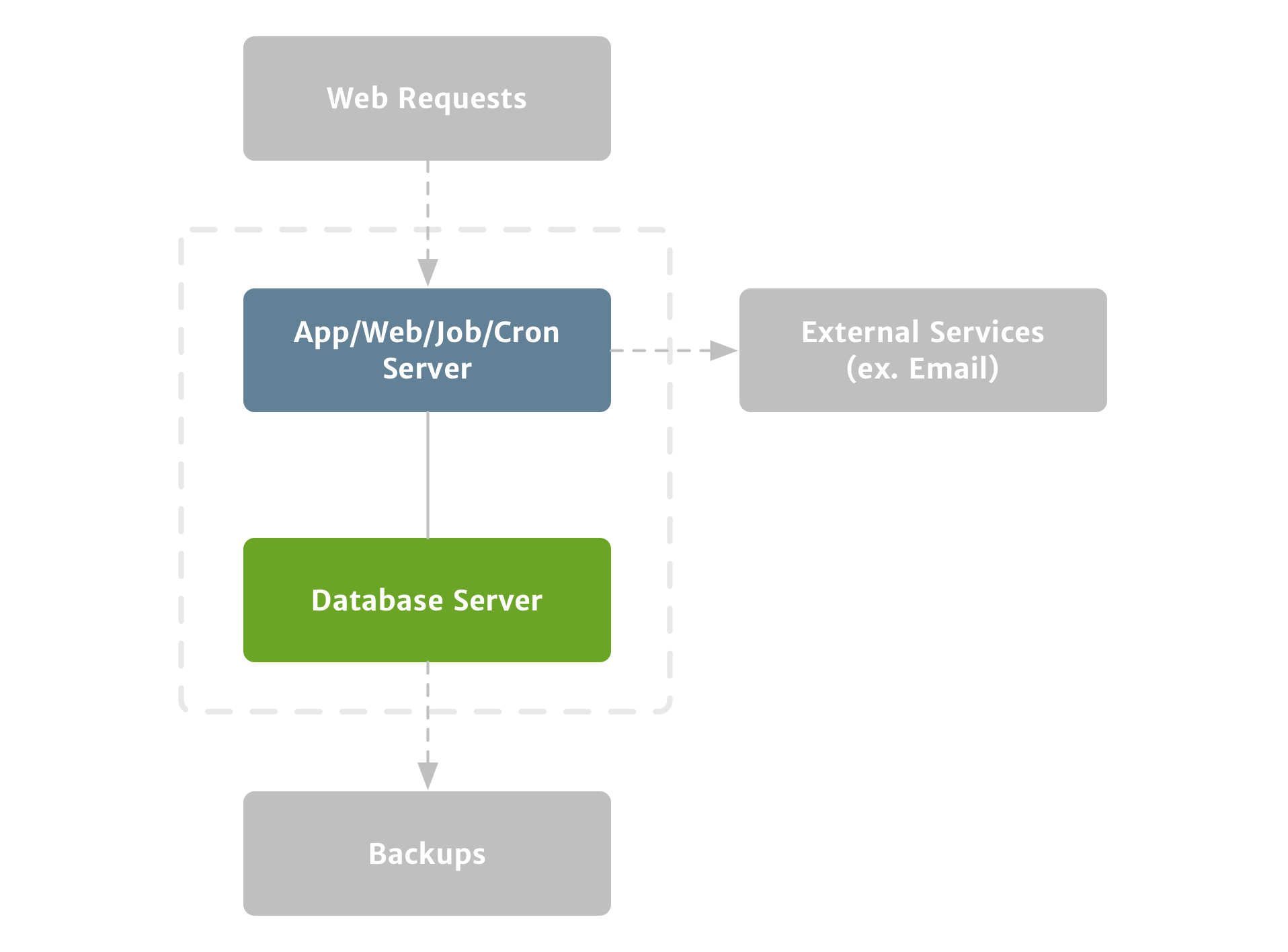
This first step protects your data from some types of issues, but it’s not fail-proof.
↩︎Off-Site Snapshot Backups
Having a replica database is important, but it’s no substitute for normal backups. For instance, if you accidentally drop a table, that change will be replicated to the replica database, and you’ll need snapshot backups to recover the deleted data. Similarly, while the chances are slim, if something catastrophic were to happen to your data center, you want to be able to keep your application up and running. That requires off-site backups.
To prevent data loss in these situations, you should take snapshots of your database and archive your encrypted snapshots in an off-site location. In our case, we kept twenty-four hours of our hourly backups, a week of our daily backups, and a month of our weekly backups on Amazon S3.
This is one area where we made some mistakes–in our early days we didn’t have a replica database and only performed off-site snapshot backups nightly. I’ll talk more in-depth about this later in the book, but the short version is that nightly backups aren’t nearly robust enough, and we learned that the hard way when we lost several hours of data for some of our customers. It could have been much worse if we didn’t have any backups, but it could have been much better if we’d had our current system in place. Don’t make the same mistake we did. Set up extensive backups from day one. (Figure 3)
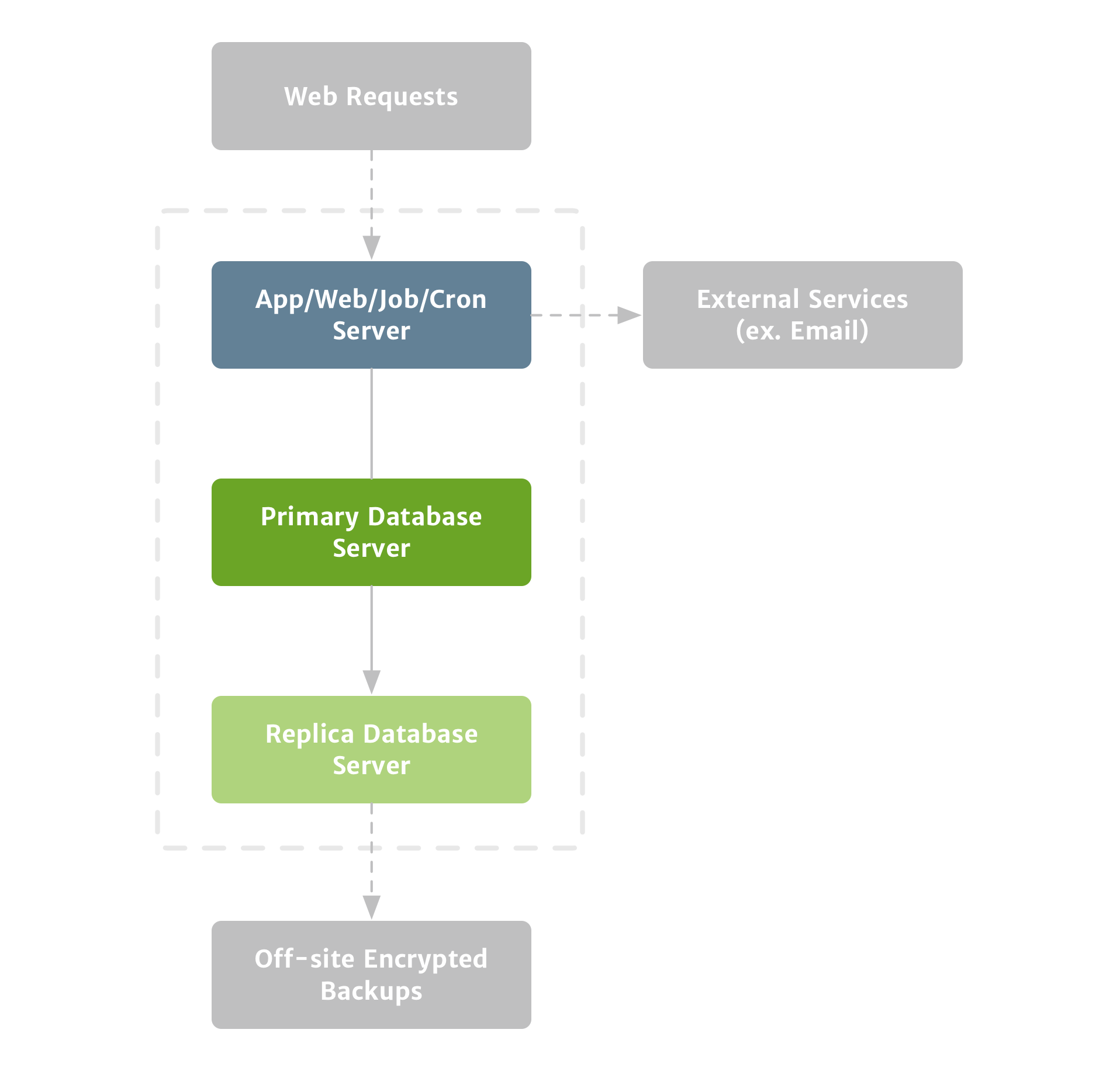
This second step ensures your data is protected from most failure scenarios.
↩︎Background Processing
Sooner or later–but probably sooner–your application will need to do some background processing. It may rely on cron to do things like run billing or clean up temporary files, or it may need to communicate with remote servers for things like sending email. In either case, you’ll probably need a dedicated server to handle this.
Any time your application communicates with another service, you’ll probably need that to be done asynchronously in the background. If it’s not, and if the remote request is slow, your customer’s request will be slow as well. Or if the remote server is offline for some reason, your customer’s request could fail entirely.
Processing remote server requests in the background helps speed up your application and ensures that jobs can be retried if they fail. The number one candidate for background processing is sending email notifications, and your app will probably be sending those using a third-party service. So it’s best to set up background processing early on.
Although you could run your background processing on your application server, it wouldn’t scale very well–as soon as you were to start adding application servers, you’d run the risk of inadvertently creating duplicate cron jobs or other scheduling conflicts. Moving your background processing onto its own server clearly separates your servers’ responsibilities. This makes your replication process easier when it comes time to scale–and giving each of your servers a focused set of responsibilities affords a little more resiliency too.
This is the most basic configuration that I’d launch with, and it’s probably the best balance of resiliency and cost for the early days. It can be done with something simpler, and many applications–including Sifter–have launched that way, but you’d be leaving a lot of room for error. This separation of tasks ensures that you can more easily scale your application. Each step beyond this is certainly nice to have, but at this level you’ll have lessened your risk for data-related issues. From this point forward, most of our focus will be on minimizing downtime. (Figure 4)
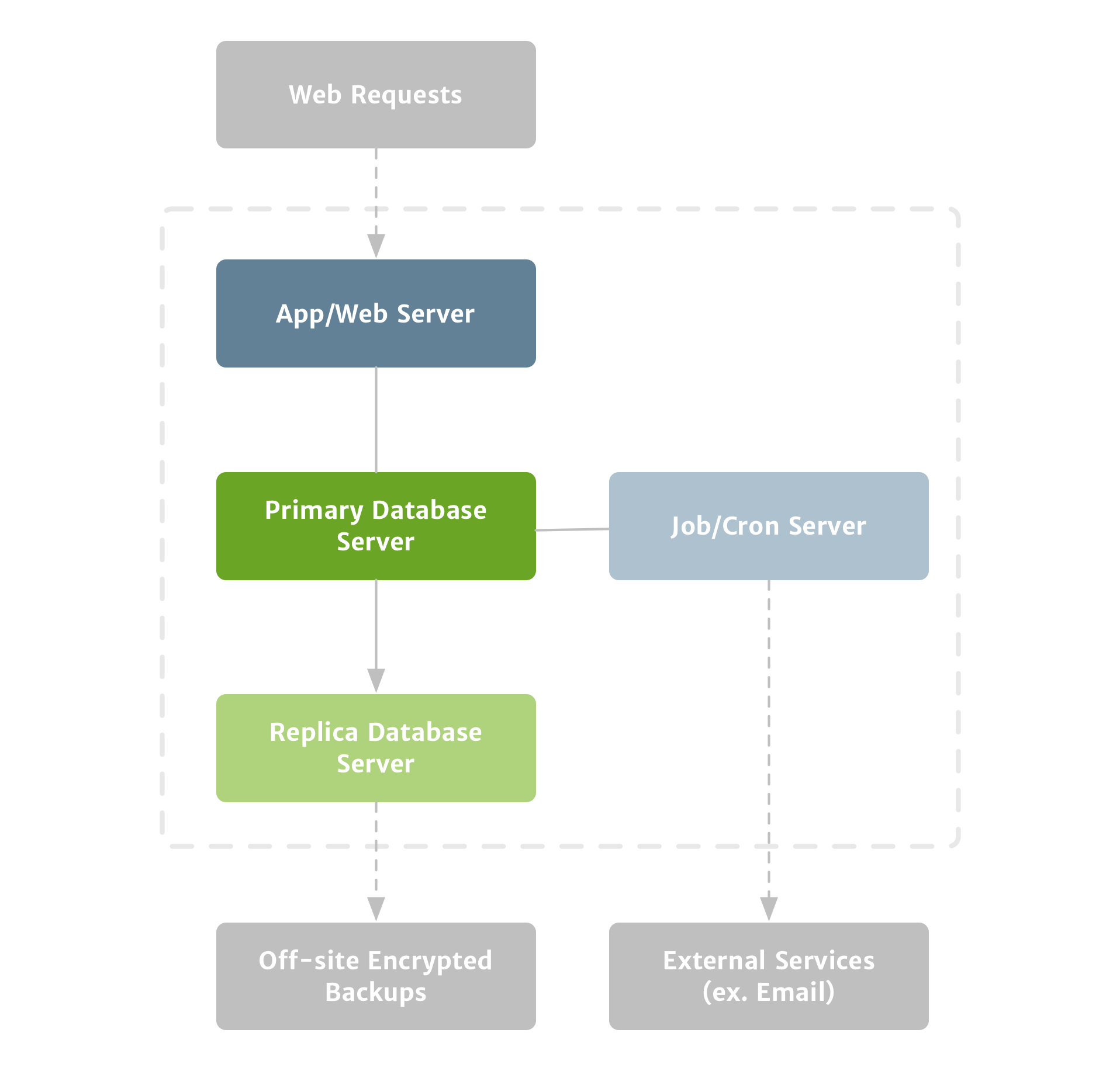
Most applications will need some form of background processing, particularly for ensuring resiliency when communicating with external services. If an external service is having temporary issues, you must be confident your application will retry the request.
↩︎Load Balancing
To increase availability, you should start minimizing your single points of failure. The first step towards that would be to add an additional application server and to place all of them behind a load balancer. With a load balancer in place, your application will spread its traffic across the two application servers, and if one of your application servers goes down or experiences performance issues, your other application server can pick up the slack until you’re able to solve the problem. (Figure 5)
While load balancing isn’t a strict requirement for launching, it can help insulate your application from some common problems. For example, when you’re using a shared server environment, a bad neighbor using too many resources can effectively take your application offline, but an extra application server help cover you.
↩︎High Availability and Failover
If you’ve never heard the phrase “five nines,” it refers to a goal of 99.999% uptime, which works out to about 5.26 minutes of downtime a year. But that’s the last thing that should be on your mind when you’re just getting started. That’s not to say you shouldn’t care about downtime, but aiming for such little downtime is overkill. It’s incredibly difficult to achieve five nines, and it’s unlikely that you’ll have enough customers spread across enough time zones for a few extra minutes of downtime during off-peak hours to matter. Unless your line of business has significant uptime requirements, I’d bet that most customers would rather you spend hours enhancing the application rather than trying to chip away at those few minutes of downtime a month. Focus on making something so good that people will care when it is offline. Then worry about perfecting your uptime.
That said, if you want to further increase your availability, your next step might be to add an additional load balancer to act as a failover in case your original load balancer were to have any problems. (Figure 6)
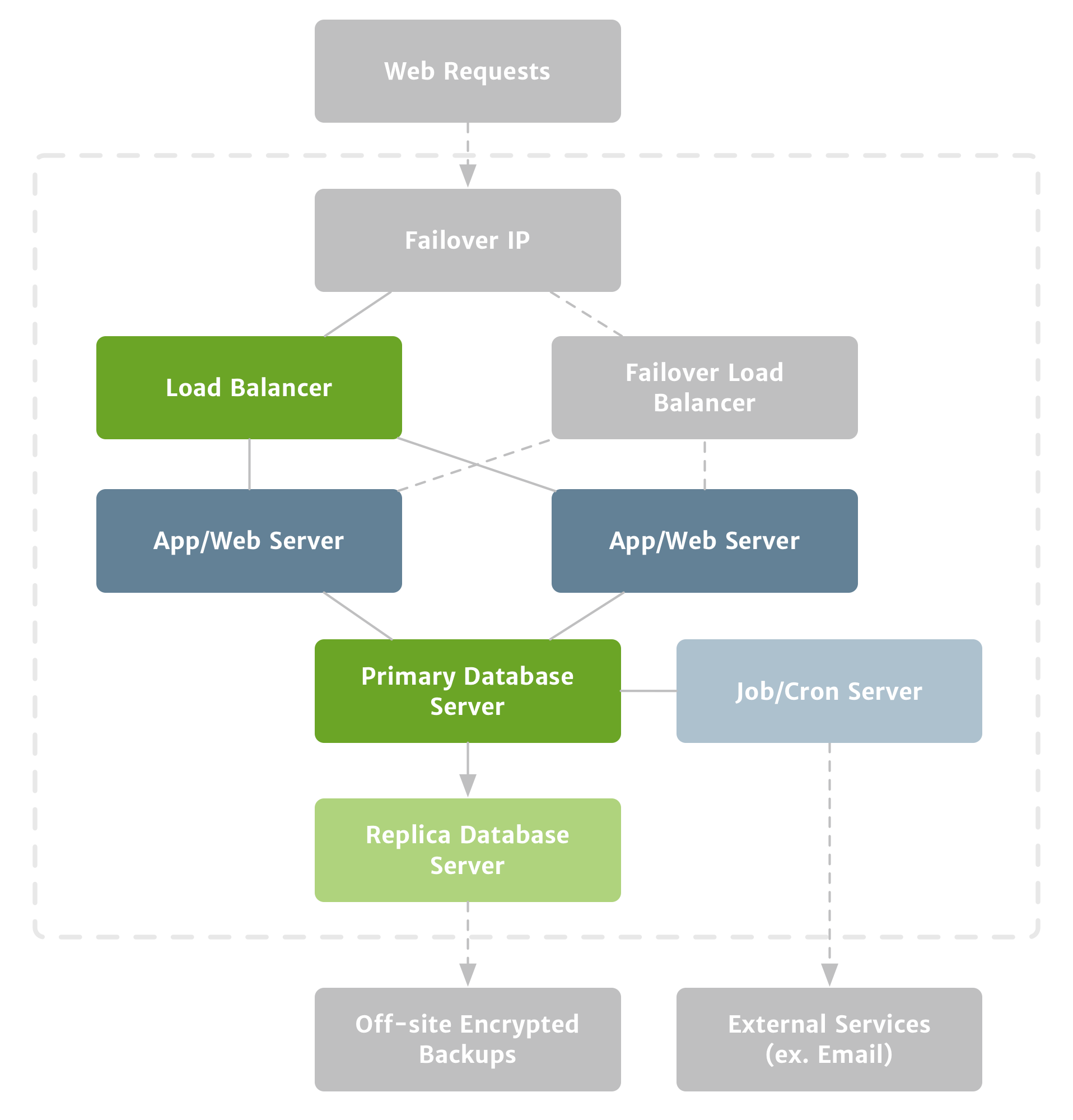
Load balancing doesn’t eliminate a single point of failure on its own, but it moves that point of failure up the chain to your load balancer. But you can add a level of failover protection for your load balancer to help mitigate that.
↩︎Managing and Updating Servers
At some point–ideally, as soon as you’re managing multiple servers–you’ll need a reliable way to provision and maintain each of your servers. The components and tools on your servers will inevitably become outdated, and many of those components will need regular updates to stay secure. You’ll also be regularly adding components and complexity to your servers. It’s incredibly easy for all this to spiral out of control if you’re not careful.
So what can you do? Keep your server configuration under source control and use a tool like Chef or Puppet that is designed for managing groups of servers. These tools will not only help minimize errors, but they’ll make it easier to update your servers and expand to multiple servers later on. You should talk to your system administrator about getting started with good configuration tools that can be kept under source control from day one.
Anecdote: Sifter’s Architecture over the Years
Sifter launched on a single virtual server. Application, web, database, everything. One server. We did just fine from a performance and availability standpoint, but this decision was also part of the biggest mistake that I ever made with Sifter. (Don’t worry–I’ll go into the gory details about this mistake later in the book.)
We decided that we’d move to a scalable and load-balanced environment as soon as we could comfortably afford it. We had started having issues where neighboring virtual machines on the host machine were affecting our performance, so we moved to a more distributed setup to insulate ourselves from these problems and prepare for the future. Unfortunately, some of our most time-consuming and difficult uptime challenges occurred specifically because of our move from a single server to a load-balanced setup; once that kind of thing is up and running, it’s great, but it definitely requires time and attention to get there.
For some context around the budget for our hosting move, we migrated from a single virtual machine to a higher-availability environment with several virtual machines that were all managed through Chef. This also increased our costs with New Relic–a performance monitoring application–because we were monitoring more servers. And we also added a monthly retainer for our system administrator. We spent about $2,000 for the move, including all the initial configuration, as well as the setup for Chef and the recipes for managing all the servers. Our total costs for hosting and monitoring, and paying our system administrator’s retainer went from $180 a month to $850 a month. That may not seem like much in the grand scheme of things, but if you’re bootstrapping, that can make a huge difference.